区域跨度:全国各省市区县
时间跨度:1980.1.1-2024.12.31(逐年逐月逐日)
正常情况下,大气温度随海拔升高而降低(大约每上升 100 米,气温约降 0.6℃),这种 “上冷下暖” 的结构会让空气自然对流,污染物随之扩散。但在某些天气下,气温却随着高度的增加而升高,就会形成 “上暖下冷”的结构 ,会导致冷空气在近地面堆积,暖空气在上方 “盖层”,空气对流受阻,危害很直接,比如近地面产生的 PM2.5、二氧化硫等污染物,无法通过对流向上扩散,只能在低空堆积,最终导致污染浓度攀升,直接影响区域空气质量。这就是逆温!
而逆温之所以成为空气污染研究的重要变量,核心在于它的双重属性:
外生性:逆温是气象条件决定的自然现象,不受人类污染排放活动直接影响,避免了 “污染影响逆温” 的反向因果问题;
相关性:逆温强度和天数直接决定污染物扩散能力,与污染浓度高度相关。
这两个双重属性,让逆温成为解决 “空气污染影响研究内生性” 的理想工具变量。
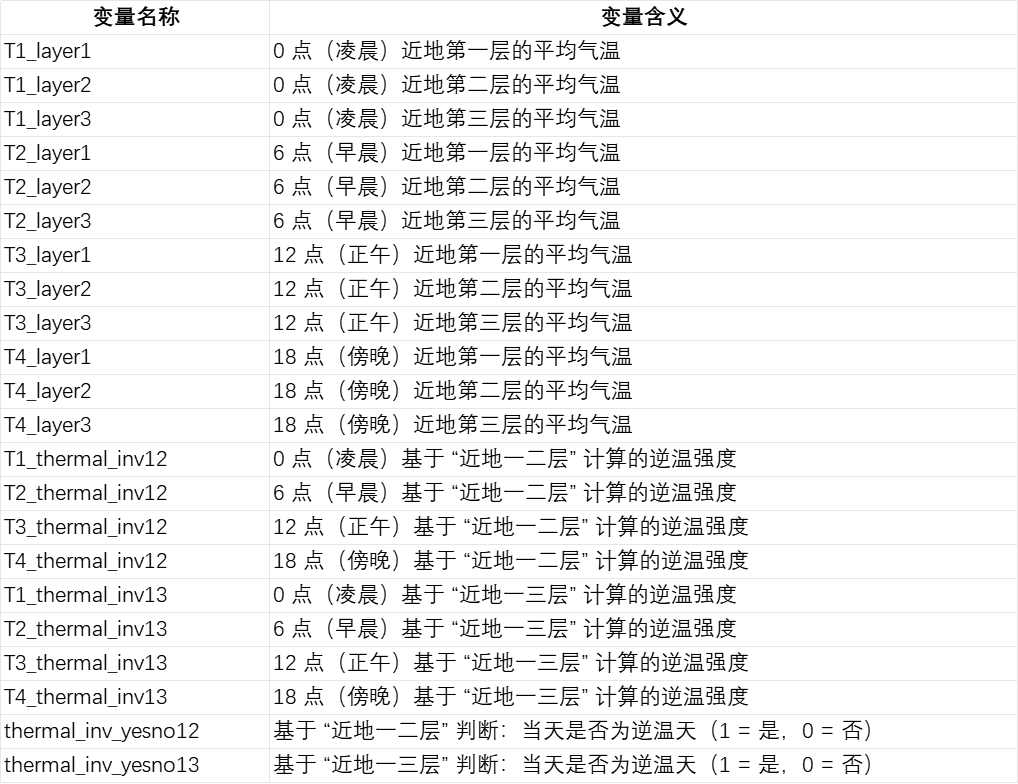
因此本“逆温”数据我们基于 NASA的MERRA-2 全球气象数据集加工,计算逻辑既参考了学术规范,又针对中国地理特点做了 “本土化调整”,因为像中国青藏高原这样的高海拔地区,底部多个气压层(对应低海拔高度)根本没有数据(海拔 5000 米以上已超过部分气压层的高度范围)。如果照搬国际通用方法(比如固定用 “320 米层气温减 110 米层气温” 判断逆温),这样计算出的高海拔区域数据会完全失真。为解决这一问题,我们做了关键优化:不固定层数,而是针对每个网格,选择 “近地面有数据的前两层” 计算。具体如下:
数据下载:从 NASA 官网下载 1980 年至今的 MERRA-2 数据集;
层数据提取:对每个网格,提取近地 “有数据的第一层、第二层、第三层” 气温(第三层用于后续稳健性检验,避免单一标准偏差);
区县匹配:将网格数据转换为 “区县面板数据”,匹配 2021 年中国县级行政区划(确保行政边界准确性);
逆温判断与强度计算:
对每天 4 个时间点(0 点、6 点、12 点、18 点),分别计算 “第二层气温 – 第一层气温”;
若差值为正:存在逆温,差值即为 “逆温强度”;
若差值为负:无逆温,逆温强度记为 0;
只要当天有 1 个时间点存在逆温,即判定为 “逆温天”。
经过上述处理,最终形成的结果数据,不仅时间跨度长,内容也极为丰富,指标如下