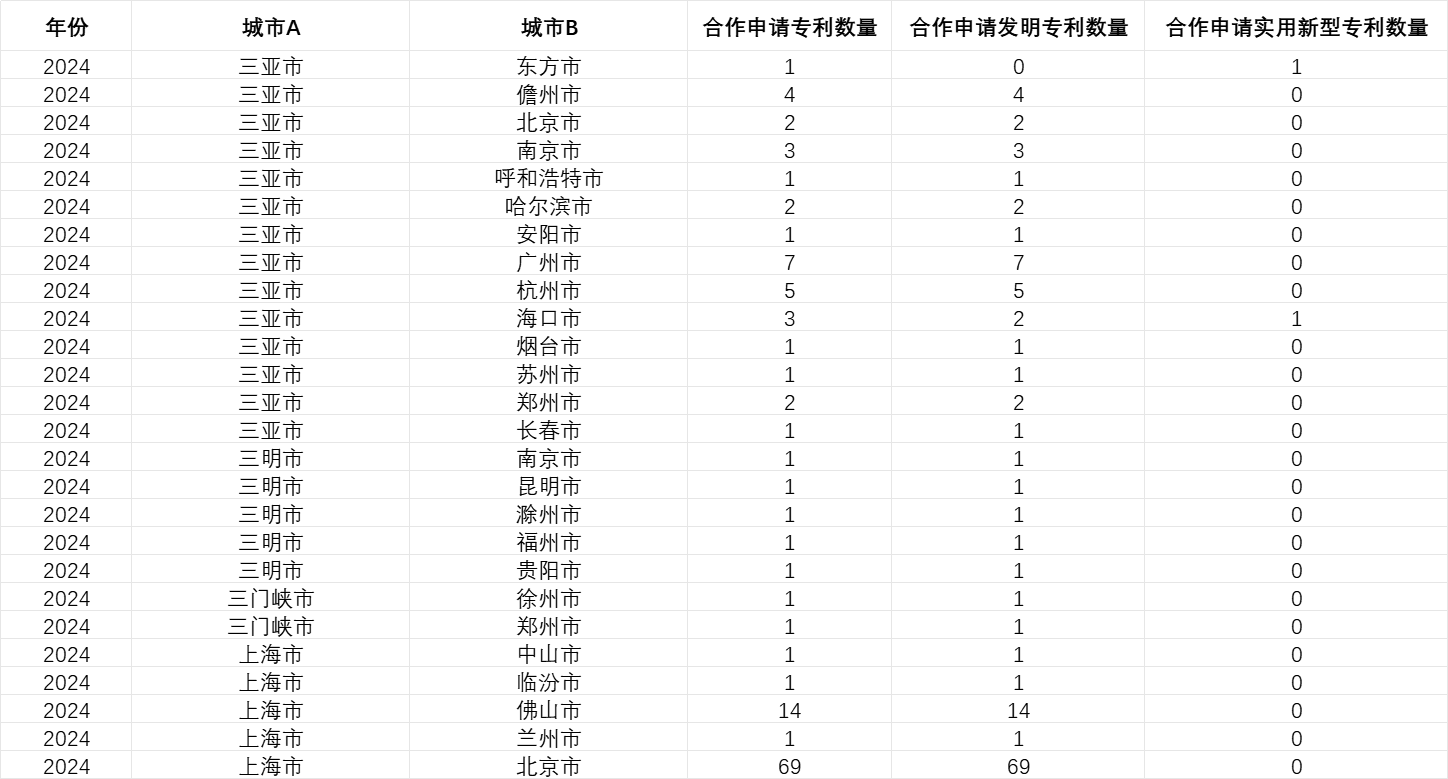
1.原始数据基础:“关键数字技术专利”
计算的前提是先明确 “统计范围”:仅纳入符合 “关键数字技术” 定义的专利,而非所有专利。依据文档提及的《关键数字技术专利分类体系 (2023)》(国家知识产权局印发),通过IPC 分类号匹配筛选专利:
先提取国家知识产权局 1990-2024 年公开的全部专利数据(含申请信息、申请人信息、专利类型、IPC 分类号等核心字段);
对照《分类体系》中划定的关键数字技术领域(如人工智能、大数据、云计算、区块链、物联网等)对应的 IPC 分类号(如 G06F16/2458 对应大数据存储、G06N3/04 对应神经网络算法等);
剔除不符合分类号的专利,仅保留 “关键数字技术领域” 的专利作为计算基数。
2.核心逻辑:界定 “合作申请” 关系
“合作数量” 的关键是判断专利是否为 “跨区域合作申请”,而非单一主体申请。具体判定规则为:
识别 “合作申请人”:若 1 件专利的 “申请人列表” 中,存在至少 2 个来自不同省 / 市 / 区县的独立主体(如企业、高校、科研院所,排除同一主体的不同分支机构),则判定为 “跨区域合作专利”;
例:若 1 件专利申请人为 “上海交通大学(上海市)” 和 “兰州大学(甘肃省)”,则属于 “上海市 – 甘肃省”(省级)、“上海市 – 兰州市”(市级)、“徐汇区 – 城关区”(区县级)的合作专利;
排除非合作场景:若所有申请人均来自同一省 / 市 / 区县(如 “华为技术有限公司(深圳市南山区)” 与 “腾讯科技有限公司(深圳市南山区)”),则仅计入该区域 “单一区域申请”,不纳入 “跨区域合作数量” 统计。
3.层级匹配:对应 “省 / 市 / 区县” 行政单元
为满足 “省份 – 城市 – 区县” 三层级统计需求,需将合作申请人的 “地理信息” 与行政层级匹配:
获取申请人所属行政区域:通过申请人注册地址(或机构所在地),定位其对应的 “省、市、区县” 行政代码(如 “北京百度网讯科技有限公司” 对应 “北京市(110000)- 海淀区(110108)”);
生成 “合作对”:对 1 件合作专利,按不同层级生成唯一 “合作对”:
避免重复统计:1 件合作专利在同一层级仅计 1 次(如上述例子中,该专利在省级层级仅算 “北京 – 上海” 1 组合作对,而非 2 组)。
4.分类统计:按 “年份 + 专利类型” 汇总数量
最终的 “合作数量” 是在上述基础上,按 “时间维度 + 专利类型维度” 进行汇总:
时间维度:以专利 “申请年份” 为基准,将合作专利归入对应年份(如 2020 年申请的合作专利,计入 2020 年统计数据);
专利类型维度:拆分 “总数量”“发明专利数量”“实用新型专利数量” 三类指标:
总数量:该合作对在某年份的所有关键数字技术合作专利数;
发明专利数量:从总数量中筛选 “专利类型 = 发明专利” 的数量(代表核心技术创新);
实用新型专利数量:从总数量中筛选 “专利类型 = 实用新型专利” 的数量(代表技术应用转化);