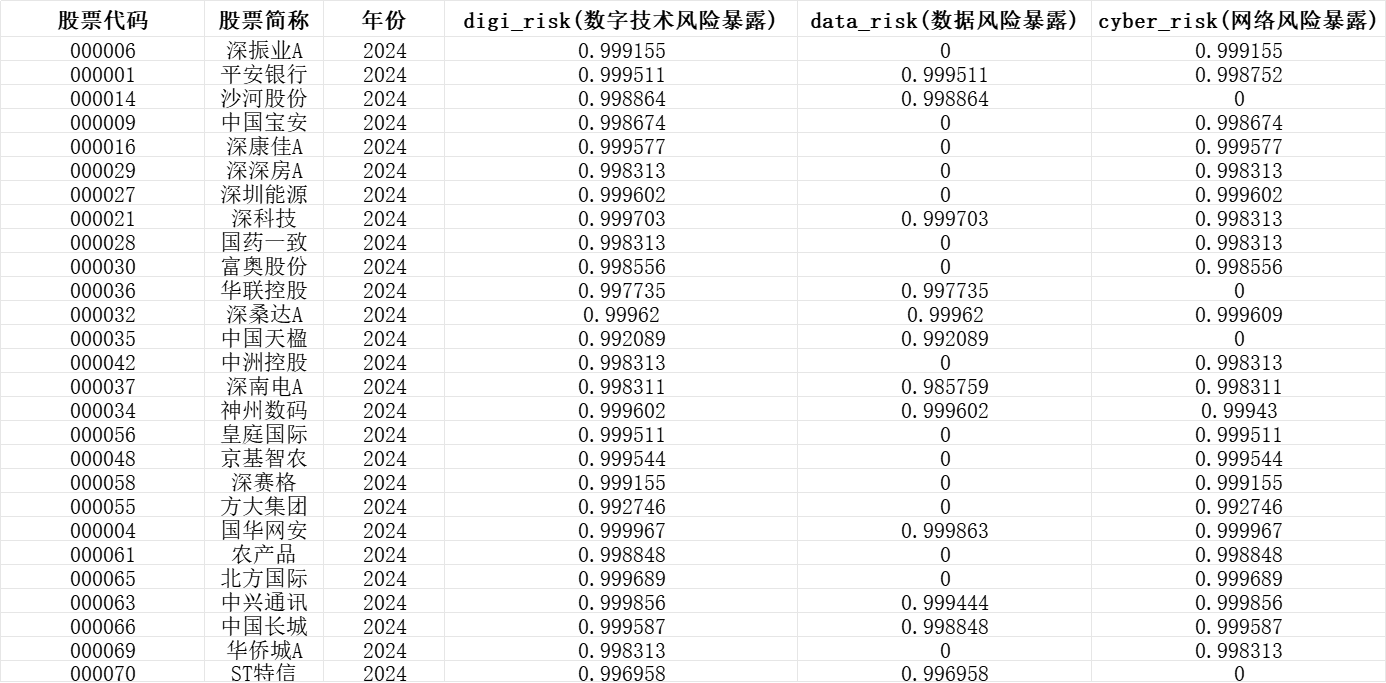
数据核心涵盖三大类风险暴露:数字技术风险暴露数据、数据风险暴露数据、网络风险暴露数据。
测算方法参考了《经济研究》期刊中陆瑶等学者(2025)的研究思路,在其基础上结合研究需求进行了方法优化。具体测算路径以 FinBERT 大语言模型为核心工具,通过对企业年度报告中与数字技术安全相关的论述开展文本情感识别,最终构建出企业—年份层面的三维度数字技术风险指标。

关于核心工具的说明:大语言模型是专注于自然语言信息处理的大型人工智能模型,其中 FinBERT 作为国内首个在金融领域大规模语料上完成训练的开源模型,具备显著领域优势。该类模型依托注意力机制,能够生成对每个词汇上下文敏感的语义表示,有效捕获文本中的长距离依赖关系与复杂语义关联,实现对语言更精准的理解与分析,整体测算流程较为复杂。
基于上述方法,最终生成的三大核心指标定义如下:
数字技术风险暴露:在企业年度报告管理层讨论与分析(MD&A)部分中,筛选出涉及数字技术风险的文本内容,以“负面文本的负面情感概率最大值”与“正面文本的正面情感概率平均值”的差值作为核心衡量指标。
数据风险暴露:针对企业MD&A部分中涉及数据风险的文本,采用与数字技术风险暴露一致的计算逻辑,即通过“负面文本负面情感概率最大值 – 正面文本正面情感概率平均值”得出结果。
网络风险暴露:聚焦企业MD&A部分中与网络风险相关的文本,以“负面文本的负面情感概率最大值减去正面文本的正面情感概率平均值”作为最终测算结果。
1. 样本规模:涵盖4.5万个观测样本,涉及5408家上市公司。
2. 配套内容:包含部分Python数据处理代码、详细测算说明文档及最终风险指标结果数据。
3. 数据来源:核心数据基于上市公司年度报告构建,选取其中管理层讨论与分析(MD&A)部分作为文本分析对象,该部分内容能全面反映企业经营相关的风险认知,确保了数据的全面性与针对性。