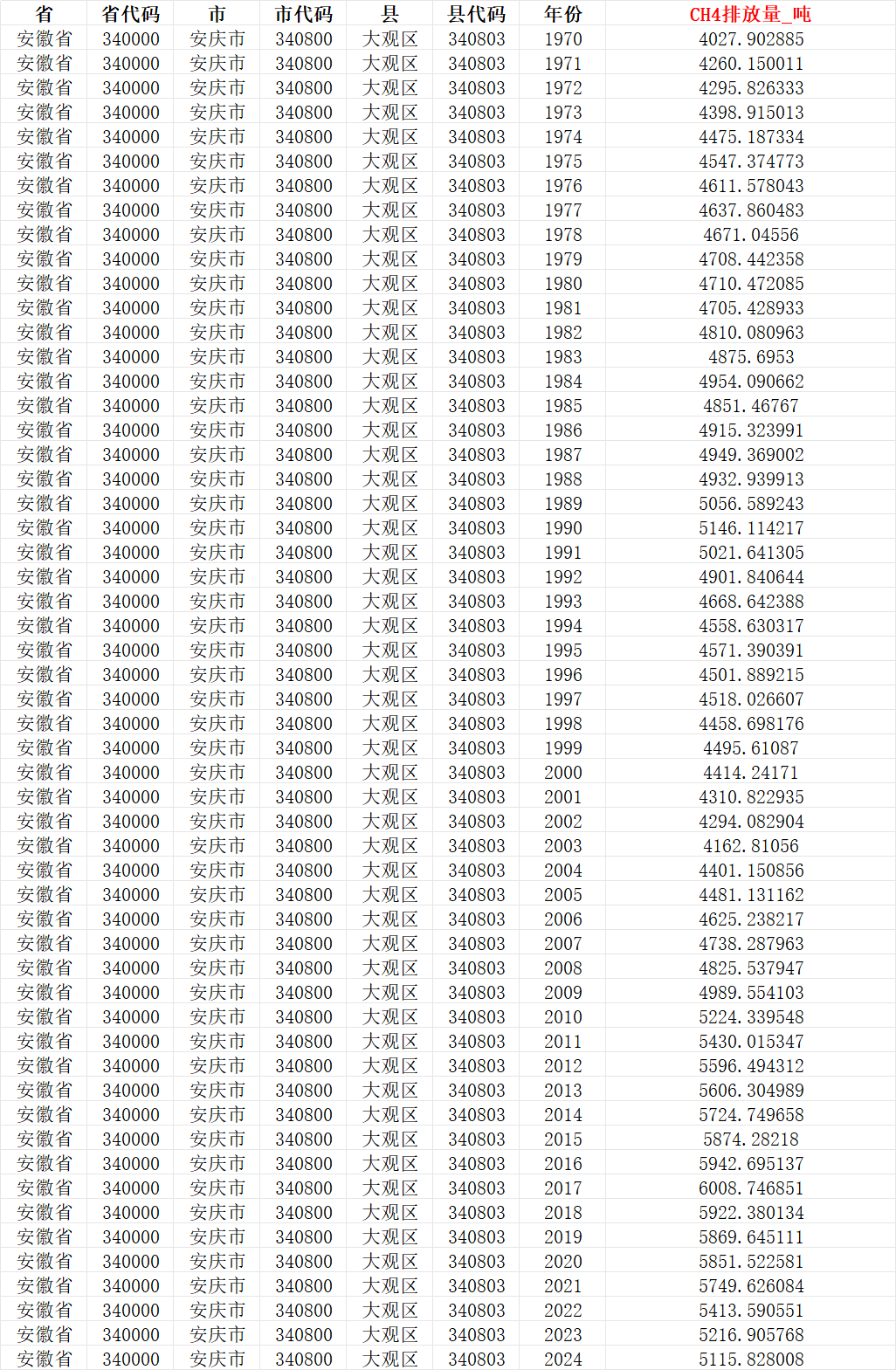
数据基于EDGAR v2025 全球温室气体排放数据库(欧洲委员会联合研究中心 JRC 开发),原始数据为 netcdf 格式,空间分辨率达0.1 度 ×0.1 度,数值计量单位为吨 / 年,覆盖全球温室气体排放的多维度监测数据。
我们从全球原始栅格数据中精准裁剪出中国行政区域范围,结合全国省 – 市 – 区县 – 乡镇四级行政区划矢量数据,通过空间关联、面积加权汇总的方式完成数据处理,全程使用 R 语言专业空间分析包实现,保证数据的精度与连续性。
CH₄排放量数据的计算分为两大核心阶段:第一阶段是 EDGAR v2025 原始 CH₄排放数据的底层核算(由欧洲委员会联合研究中心 JRC 完成),第二阶段是从原始栅格数据到中国省 / 市 / 区县 / 乡镇四级面板数据的空间加权汇总计算(由数据处理方基于 R 语言完成),两个阶段层层递进,以下是详细的计算逻辑和步骤:
一、底层基础:EDGAR v2025 原始 CH₄数据的核算方法
EDGAR v2025 作为全球权威的温室气体排放数据库,其 CH₄排放量核算以 IPCC(联合国政府间气候变化专门委员会)指南为核心,采用技术细分的排放因子法,是全球统一、标准化的核算体系,也是本次分享数据的源头基础EDGAR。
1. 核心核算公式
EDGAR 对每个国家、每年、每个行业的 CH₄排放量计算,核心公式为:EMC,x,y,i=ADC,y,i×TECHC,y,i,j×(1−EOPC,y,i,j,k)×EFC,y,i,j×(1−REDC,y,i,j,k)参数说明:
EMC,x,y,i:国家 C 在 y 年 i 行业的 CH₄排放量;
ADC,y,i,j:国家 C 在 y 年 i 行业 j 技术的活动数据(如农业畜禽存栏量、能源天然气消耗量、废弃物处理量等,是产生 CH₄的基础活动量化指标);
TECHC,y,i,j:i 行业中 j 技术的使用占比;
EOPC,y,i,j,k:末端治理措施 k 的减排比例;
EFC,y,i,j:i 行业 j 技术对应的CH₄排放因子(IPCC/EDGAR 提供全球统一 + 区域化的缺省值,如反刍动物肠道发酵的 CH₄排放因子、天然气泄漏的 CH₄排放因子);
REDC,y,i,j,k:减排技术带来的排放因子削减比例。
2. 核心核算原则
覆盖全人为排放源:CH₄排放主要来自农业(畜禽养殖、水稻种植)、能源(化石燃料燃烧、天然气泄漏)、工业(化工生产)、废弃物(垃圾填埋、污水处理)四大领域,EDGAR 会分源逐一核算后汇总;
空间初始分配:核算出的国家尺度排放量,会结合地理代理数据(如人口密度、农业用地分布、能源设施位置、道路网络等),分配到0.1 度 ×0.1 度的全球栅格单元中,形成 netcdf 格式的栅格数据,单位为吨 / 年,这也是本次数据处理的原始输入文件EDGAR。
二、核心处理:从原始栅格到四级面板数据的面积加权汇总计算
EDGAR 原始数据是全球栅格格式,无法直接用于中国行政区划的分析,因此数据处理方通过 R 语言(terra/sf/ncdf4 等包),对原始数据进行中国区域裁剪、空间匹配、面积加权汇总,最终得到省 / 市 / 区县 / 乡镇四级面板数据,这是本次数据的核心计算环节,面积加权法是整个过程的关键(解决栅格像元跨行政区划的问题)。
核心计算逻辑
单个栅格像元的 CH₄排放量是固定的,但一个像元可能跨越多个行政区(如一个 0.1 度栅格同时覆盖 A 县和 B 县),因此某一行政区的 CH₄排放量 =Σ(覆盖该行政区的每个栅格像元的 CH₄排放量 × 该像元在该行政区内的面积占比),通过面积占比加权,保证排放量在行政区划上的精准分配。
具体计算步骤(基于 R 语言实现)
结合文档中提到的处理流程和代码片段,具体步骤分为 5 步,全程可通过并行计算(makeCluster(12))提升效率:
步骤 1:原始栅格数据预处理
用ncdf4包读取 EDGAR v2025 的 CH₄栅格数据(netcdf 格式),用terra包转换为栅格对象(RasterLayer);
导入中国国界矢量数据,对全球栅格数据进行裁剪,只保留中国行政区域内的栅格像元,剔除境外数据;
统一空间坐标系(如 WGS84),保证栅格数据与后续行政区划矢量数据的空间匹配性。
步骤 2:准备四级行政区划矢量数据
导入中国省 – 市 – 区县 – 乡镇四级行政区划的矢量面数据(含行政区划名称、国标代码),并完成:
矢量数据的坐标系与栅格数据统一;
对矢量数据进行拓扑检查(修正重叠、缝隙等问题),保证空间计算的准确性。
步骤 3:栅格与行政区的空间叠加分析
用sf包对裁剪后的 CH₄栅格数据和行政区划矢量数据进行空间叠加(Intersect),生成新的空间要素:
每个新要素为 “栅格像元 + 行政区” 的交集部分,同时包含栅格的 CH₄排放量、行政区的编码 / 名称、交集部分的面积;
计算每个原始栅格像元在各相交行政区内的面积占比(交集面积 / 原始栅格像元总面积)。
步骤 4:面积加权计算各行政区 CH₄排放量
对叠加后的空间要素,按行政区划编码分组,执行加权求和计算:行政区排放量栅格像元的排放量栅格像元在该行政区的面积占比
N 为覆盖该行政区的所有栅格像元数量;
按此方法,逐级完成乡镇、区县、市、省四级行政区的排放量计算,保证上下级数据的汇总一致性(如省级排放量 = 省内所有市级排放量之和)。
步骤 5:时间序列整合与数据校验
对 1970~2024 年共 55 年的栅格数据,重复上述 1-4 步,完成每年四级行政区的 CH₄排放量计算;
将每年的计算结果按行政区划编码 + 年份整合,生成 Excel 格式的面板数据(含编码、名称、年份、排放量核心字段);
进行数据校验:检查时间序列的连续性、上下级行政区的汇总一致性、异常值(如排放量为负、畸高)修正,最终得到四份面板数据文件。
三、不同尺度数据的计算特点
省级 / 市级数据:栅格像元的跨区比例相对较小,计算效率高,是区县 / 乡镇数据的汇总基础;
区县 / 乡镇数据:行政区划更精细,栅格像元跨区情况更频繁,对空间叠加和面积加权的精度要求更高,也是本次数据处理的重点;
乡镇数据:为了方便使用,直接将 1970~2024 年各年份的排放量作为列变量,无需额外整理时间序列,计算后直接按乡镇编码整合。
四、配套栅格数据的计算说明
文档中同时提供的中国范围 CH₄栅格数据,无需额外的面积加权计算,仅对 EDGAR 原始栅格数据进行了中国区域裁剪、格式转换(可保留 netcdf/tif 格式),保留了原始 0.1 度 ×0.1 度的分辨率和吨 / 年的单位,可直接导入 ArcGIS/QGIS/R/Python 进行空间分析。